Making multi-cloud work: Cloud Data Services
How to unlock the power of data availability with multi-cloud
Over the past decade, most organizations have taken advantage of the scale and flexibility of cloud services and platforms. As each public cloud provider develops specialized capabilities, organizations are building strategies and adopting technology to facilitate a multi-cloud implementation. A recent Gartner survey finds that 81% of respondents are already using two or more cloud providers, but a well-planned multi-cloud strategy goes beyond simply connecting to two clouds and improves integration, reduces overhead, and simplifies data access.
What is multi-cloud?
Multi-cloud is the utilization of two or more public cloud providers to serve an organization’s IT services and infrastructure. There is no single multi-cloud vendor. A multi-cloud approach typically consists of a mix of major public cloud providers, namely Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft (Azure), and IBM. Organizations choose the best services from each cloud provider based on costs, technical requirements, geographic availability, and other factors. This may mean that a company uses Google Cloud for development/test, while using AWS for disaster recovery, and Microsoft Azure to process business analytics data.
Data availability challenges in multi-cloud environments
In addition to the advantages, multi-cloud adoption can present an entirely new set of challenges. One of these challenges, data availability, is the process of maintaining access to your data at your required level of performance in situations ranging from normal everyday operations to disaster recovery operations.
Individual cloud providers have already solved many of these data availability problems within the context of their own clouds or services. Cross-service consumption, cross-region replication, snapshots, and backups, are all services cloud providers currently offer to help combat data availability problems.
What happens though, when we start thinking about the same data across multiple cloud providers? Organizations would need to take on the role of coordinating data availability and security across multiple cloud providers. Ask these questions before attempting to use the same data sets across clouds:
- How do I take the output from a service in one cloud provider and use it as input for a service in another cloud provider?
- How do I implement consistent data management policies across multiple cloud providers?
- How can I safely read and write to the same data set across multiple cloud providers?
- How can I manage capacity and performance across multiple cloud providers to ensure consistent performance?
These are just a few examples of the data availability challenges you might encounter when implementing a multi-cloud strategy.
How to Choose a Cloud Data Service
Organizations are increasingly relying on cloud provider services to offload large portions of their application stacks. For example: databases, message queues, batch processing, load balancing, and traffic management, just to name a few. If we wanted to treat data the same way, how would an organization choose a “data-as-a-service” provider? For starters, that provider would need to resolve the availability problems in a multi-cloud environment. Let’s look at the full list of criteria:
1. Geography
The service would need to be geographically proximate to the cloud providers an organization is using. Light only allows data to travel so fast, so being as close as possible ensures acceptable levels of latency. If the organization uses clouds located in the “US-East (Virginia)” region, they would work with Cloud Data Services providers that also reside in this region.
Not all data center providers in the region are created equal. Choosing the correct geographic location and datacenter partner can significantly improve latency, but choosing the wrong one can hinder your productivity. Some providers offer round trip latency under 1ms to both AWS and Microsoft Azure in the “US-East (Virginia)” region. However, in the same region, other providers’ services can reach as high as 2ms round trip latency. Choosing a provider that provides low latency to all targeted public cloud providers will provide consistent performance and improve throughput (IOPS) to the storage service.
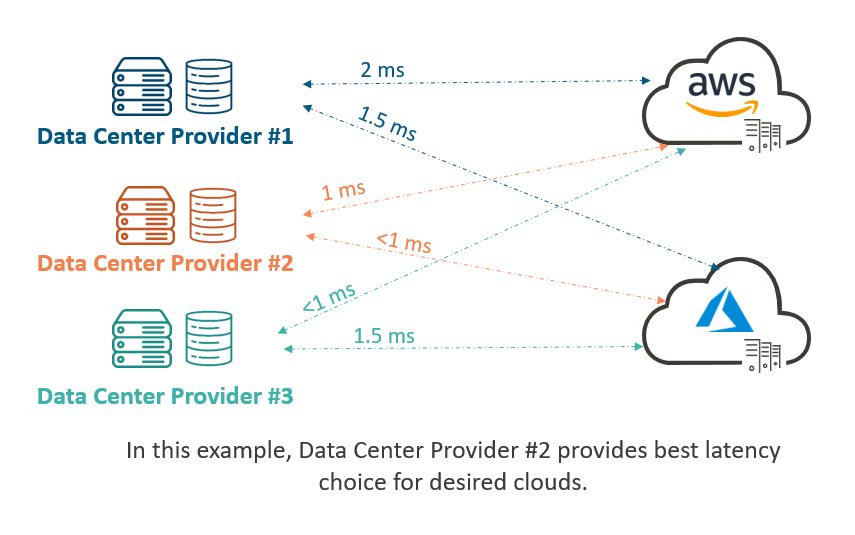 Choosing the correct data center provider can have a significant impact on latency and performance of Cloud Data Services.
Choosing the correct data center provider can have a significant impact on latency and performance of Cloud Data Services.
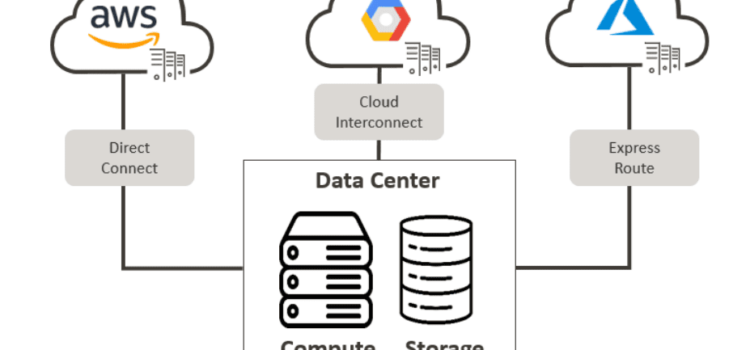
2. Connectivity
The service would need the ability to securely connect to the cloud providers your organization is using. The ideal service would provide a low-latency connection, with adequate throughput, to consume the storage service. This would include using services like DirectConnect for AWS, ExpressRoute for Azure, and Cloud Interconnect for GCP.
 3. Consumption
3. Consumption
 3. Consumption
3. ConsumptionLook for a service that allows all of your cloud providers to simultaneously access your data. Without simultaneous access, an organization’s choices for service consumption are limited to the public cloud where the data is accessible. Having simultaneous access to the same data set from multiple cloud providers allows organizations to put services from different providers in head-to-head competition.
Using file systems and protocols that support file locking allows the service to provide this functionality. NFS and CIFS are commonly used to meet these requirements.
The service would also need to provide a flexible endpoint consumption model. Your organization may want to consume storage from the same IP space across all of your cloud providers, or your organization may want a unique IP space for each cloud provider. Having the flexibility to choose which IP space you consume the data from provides organizations the ability to adhere to any existing IP schema requirements and standards. Organizations are not required to compromise the ability to consume data from a singular storage platform, while still maintaining flexibility in the data consumption methods.
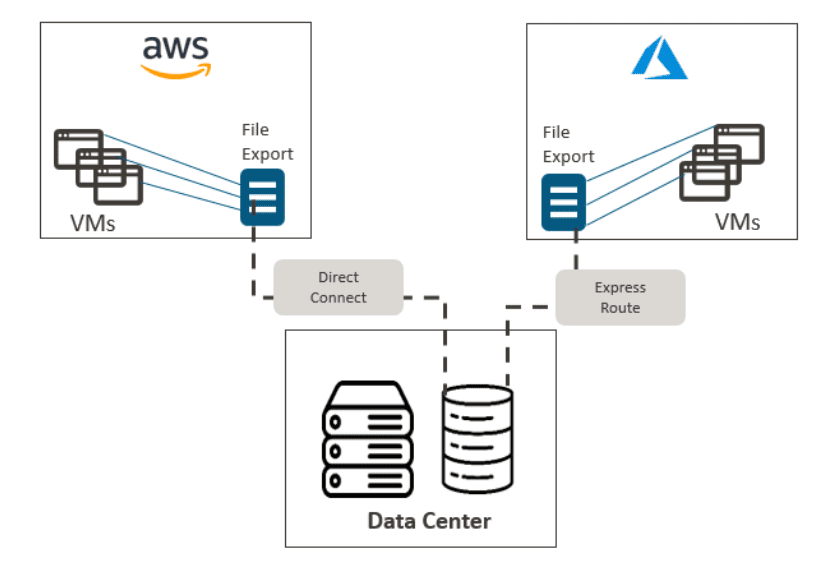 Being able to consume data as a service across multiple cloud providers can change the way we think about and consume cloud services. Organizations will be able to shift from one cloud to another, or use multiple clouds simultaneously, to take advantage of cloud innovations and cost savings — all without worrying about data portability.
Being able to consume data as a service across multiple cloud providers can change the way we think about and consume cloud services. Organizations will be able to shift from one cloud to another, or use multiple clouds simultaneously, to take advantage of cloud innovations and cost savings — all without worrying about data portability.
Organizations can ingest the data using one provider, process the data with a second provider, and maybe even visualize the data with a third provider. The sky really is the limit when it comes to flexibility and innovation potential this provides. It gives organizations the opportunity to spend less time thinking about how to manage data and spend more time thinking about how to use the data.
Learn more about Cloud Data Services
If you’re interested in learning more about Cloud Data Services, Faction is helping organizations solve multi-cloud data availability problems by abstracting their data from individual cloud providers so it can be consumed as a service. When data is abstracted from the cloud, the complexities of data protection and disaster recovery are reduced. With this unique architecture, a single copy of data can be accessed by all clouds simultaneously for all the clouds, cutting storage costs by 3-4x. As an additional benefit, organizations retain centralized control and boost innovation through access to the latest best-in-class services from multiple cloud providers. Want to learn more? Contact Us.
About the author:
Corey Dickson is a Professional Services Engineer who has been with Faction for 3 years focusing on Cloud Services Delivery and Cloud Migrations.