An Overview of Data Repository Types: Data Lakes, Data Warehouses, and Data Lakehouses
Innovation in data is rapidly leading to changes in how data is stored and accessed. As enterprise architects and others rely on data repositories to help inform decision-making and deliver meaningful business insights, it’s helpful to have an overview of convergence in the space of data repositories. Each can vary based on the types of data it ingests and analyzes; its purpose, intended users, and flexibility; cost-effectiveness; and more.
What are the different Data Repository Types?
Here, let’s take a look at data lakes, data warehouses, and data lakehouses.
Data Lakes
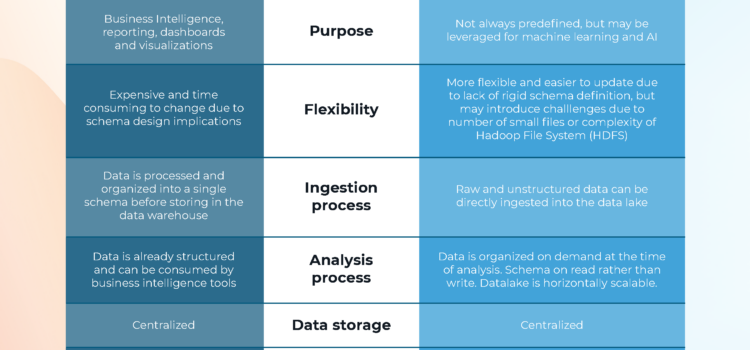
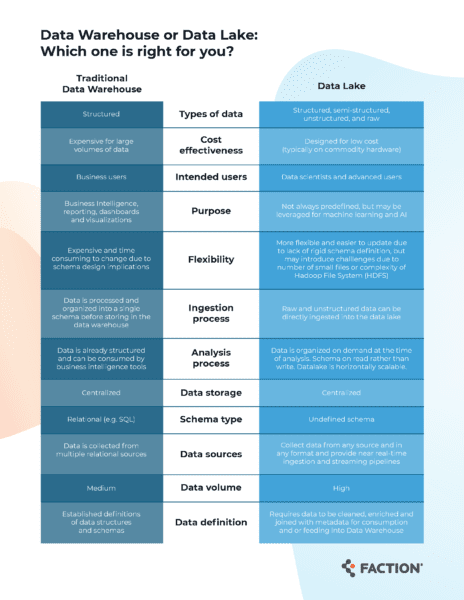
A data lake is a highly scalable storage repository that ingests data in its raw format. That data then gets cleansed, validated, and processed through streaming pipelines. Data can be stored into tables for reports and dashboards or made available to feed other downstream systems, such as data warehouses or can be served from the Data Lake itself assuming a serving layer has been defined (NOTE: there are numerous databases that can be used to serve data on the data lake). The raw data is always preserved by subject/data/time so that it can be replayed (by the pipeline) at any time.
In a data lake, data often comes from disparate sources and can include a mix of structured, semi-structured, and unstructured data formats. A data lake allows you to perform ELT (extract, load, transform) operations on data. Data is stored with a flat architecture and can be queried as needed.
For companies that need to collect and store a lot of data but don’t necessarily need to process and analyze all of it right away, a data lake offers an effective solution. Data lakes can load and store large amounts of data very rapidly with or without transformation.

Data Warehouses
On the other hand, traditional data warehouses usually rely on third-party tools prior to “landing” into the data warehouse. Such tools include Informatica, Mulesoft, or other ETL (extract, transform, load) tools.
Traditional data warehouses handled only structured data, but more modern data warehouses can not only perform ELT operations but also can ingest structured, semi-structured, and in some cases unstructured data. requiring the ETL process to transform the data being ingested to fit the data warehouse scheme. Modern data warehouses, like Yellowbrick, can perform ELT operations; this makes the data warehouse a speed area for consuming the data, handling structured, semi-structured, and unstructured data.
For a more detailed evaluation of what may be right for you:
- Read Before selecting a data warehouse strategy, take these 3 steps
- Download the Data Warehouse/Data Lake Comparison Cheat Sheet
Data Lakehouses
Data lakes can be very cost-effective for data storage, but they lack the architecture that typically defines a data warehouse. Data warehouses and data lakes have converged over the years, leading to a new concept. Data lakehouses, a term initially coined by Pedro Javier Gonzales Alonso in 2016, combine various elements and advantages of a data warehouse and a data lake.
A data lakehouse provides the best of both worlds. It can lower administration and governance efforts and require less movement of data. A powerful use case for a data lakehouse is to leverage it as a data source for machine learning (ML) and business intelligence (BI).
Read more about how to overcome challenges facing Enterprise Architects and download our new whitepaper.
