What is Data Gravity? How it Can Influence Your Cloud Strategy
The amount of data that is generated every day is amazing. The latest statistics show that 1.7 MB of data is created every second or 146.88 zettabytes every day. While your business may generate just a small slice of this massive amount, effectively managing all of their data has become a challenge for even the largest enterprises.
Artificial intelligence, machine learning, deep learning, advanced data analytics, and other data-intensive applications provide better insight than ever before. However, managing and utilizing these large data sets requires a new way of approaching your cloud architecture. In order to do this, it’s important to understand the concept of data gravity.
What is Data Gravity?
When working with larger and larger datasets, moving the data around to various applications becomes cumbersome and expensive. This effect is known as data gravity.
The term data gravity was first coined by Dave McCrory, a software engineer, in trying to explain the idea that large masses of data exert a gravitational pull on IT systems. In physics, natural law says that objects with sufficient mass will pull objects with less mass towards them. This principle is why the moon orbits around the earth, and the earth revolves around the sun.
Data doesn’t literally create a gravitational pull, but smaller applications and other bodies of data seem to gather around large data masses. As data sets and applications associated with these masses continue to grow larger, it becomes increasingly difficult to move. This creates the data gravity problem.
Data gravity hinders an enterprise’s ability to be nimble or innovative whenever it becomes severe enough to lock you into a single cloud provider or an on-premises data center. To overcome the consequences of data gravity, organizations are looking to data services that simultaneously connect to multiple clouds.
How Does Data Gravity Influence Your Cloud Strategy?
As providers like AWS, Azure, and Google Cloud compete to be the primary cloud computing provider for companies, it seems like they all have a pitch to convince you to migrate to their cloud. Adopting one or more clouds might make things run more smoothly for your business needs, but does it make sense for your data?
The massive amounts of data generated — both in terms of the scope of datasets and in the gravitational pull of that big data — multiply the requirements for additional capacity and services to utilize it. Data Gravity encompasses what happens to big data in cloud services.
For many enterprises, the associated costs are crushing. Large data sets can increase the fees to access your data — doubling the costs to host, replicate, and sync duplicate data sets can all impede your budget and business success.

There are two challenges to solving the gravitational pull of massive amounts of data: latency and scale. The speed of light is a hard limit on how quickly data can be transferred between sites, so placing data as close to your cloud computing applications and services as possible will reduce latency. As your data increases in size, it becomes more difficult to move it around.
Let’s look at a couple of cloud strategies organizations use to address the major challenge of Data Gravity.
Data Gravity and Latency
One approach to reducing latency is putting all of your data in a single cloud. Like the proverbial warning about putting all of your eggs in one basket, this path introduces a few drawbacks. The reasons include:
- Compatibility — Your cloud provider’s storage solutions may not fit your use case as well as you might want or need, and require additional services for functionality that may not be expected or budgeted.
- Fees — Not only are you paying for the base data storage costs with cloud provider storage, but cloud providers may charge you transaction and egress fees when you need to access it.
Each cloud provider promises agility, flexibility, lower costs, and superior services and toolsets, but the reality can be unforgiving. Instead of increased agility and flexibility, your developers may become hamstrung by the single cloud implementation.
Things may start out fine as you start with a vendor that meets your needs at the time, but as time passes, there may be better solutions available. Instead of being able to use these better options, you may get trapped with a provider (“vendor lock-in”) because it’s too difficult or expensive to move the data.
Instead of lowered costs, you’re sitting on a mountain of egress fees or paying for a mismatch in performance levels.
Data Gravity, Storage, and Cloud Computing
Duplicated data, outside of backups or DR strategies, is wasteful, so maintaining a single big data repository or data lake is the best method to avoid siloed and disparate datasets.
Rather than using a data warehouse, which requires conformity in data, a data lake with appropriate security can handle your raw data and content from multiple data sources.
A data lake with cost-effective scalability seems easy enough, and it can be — depending on the data needs at enterprises. Many organizations have a suitable on-premises data lake, but accessing that data lake from the cloud has several challenges:
- Latency – The further you are from your cloud, the more latent your experience will be. For every doubling in round trip time (RTT), per-flow throughput is halved. This can cause a greater likelihood of slowdown, especially for data-intensive data analytics that leverages artificial intelligence and machine learning.
- Connectivity – Ordering and managing dedicated network links, such as AWS Direct Connect or Google Cloud dedicated Interconnect, can be costly. Balancing redundancy, performance, and operational costs is difficult.
- Support – Operating and maintaining storage systems is generally expensive and complicated enough to require dedicated expert personnel.
- Capacity – A location and infrastructure plan and budget for growth are required.
On-premises data lakes can address latency by co-locating closer to public cloud locations and by purchasing direct network connections. Still, the cost is prohibitive for midsized companies who wish to leverage the innovative services of multiple clouds.

The Multi-Cloud Solution: Avoiding Vendor Lock-in
According to Gartner, by 2024, two-thirds of organizations will use a multi-cloud strategy to reduce vendor dependency. Cloud-native storage tiers on AWS, Google Cloud, and Azure can be matched to the performance and access frequency of different types of data processing but can only be accessed from their own cloud location.
If your developers and business teams use multiple services from different clouds that all need access to the same body of data, these cloud provider storage solutions may become a trap. External, remote, or cross-cloud access may be closed off. Cross-availability zone access within the same cloud or replication can become more difficult.
Even a simple method for seeding data, for example, can become a pain point.
Sidestepping these issues may require duplicating your datasets – adding cost and management overhead — for data analytics. While you may have solved the problem of vendor dependency, this approach still has data access and cost implications.
Overcoming Data Inertia: Future Proof Your Data with Multi-Cloud
If enterprises have sunk costs in equipment that may not be fully depreciated, legacy applications that are unsuitable for cloud-native deployment designs, or data compliance requirements, overcoming inertia to access the benefits of a multi-cloud strategy may seem impossible. It’s helpful to change the goal from “how do I get my app in the cloud” to “how do I use my data from the cloud?”
This perspective change that places your data at the center of your strategy will help your organization chart a path that future-proofs your data and makes the idea of leveraging competitive services from each of the clouds possible.
When solving for multi-cloud data access, ask these questions:
- How do I minimize real-time latency?
- How do I keep my data secure?
- What is the most efficient way to access my data from anywhere?
- How do I minimize my fees?
For example, some challenges, like cross-cloud access, can add such complexity or cost that the design becomes untenable. The real dream killer, though, is latency.
No matter how awesome your storage array is, no matter how fat your network pipes are, storage performance is a function of latency, and distance is the enemy.
Overcoming data gravity allows you to leverage big data for better insight and data analysis.
Where’s the Right Location for My Data?
Where can you put your data that allows for multi-cloud access at low latency? Adjacency is the proper solution to latency, and the cloud edge is the logical answer, but what does that really mean?
Colocated Data Lake
Colocation data centers that are adjacent to cloud locations can enable data collection and access from multiple clouds, a significant improvement over the data duplication that comes with copies of the same data in each cloud’s native storage.
Because organizations often manage their own equipment in a colocation agreement, the responsibility of cross-referencing possible colo data centers with desired public clouds to validate low latency requirements falls on the customer’s organization. If that organization needs cross-region access, your business logic may require additional colocation sites (and higher costs). You may also have charges for extra regions with multi-cloud data services as well.
Finally, cross-connects and private circuit options, along with hyper-scaler onramps, introduce additional unknowns and will certainly increase the cost. Leveraging them safely and effectively may be more effort than you are prepared to shoulder.
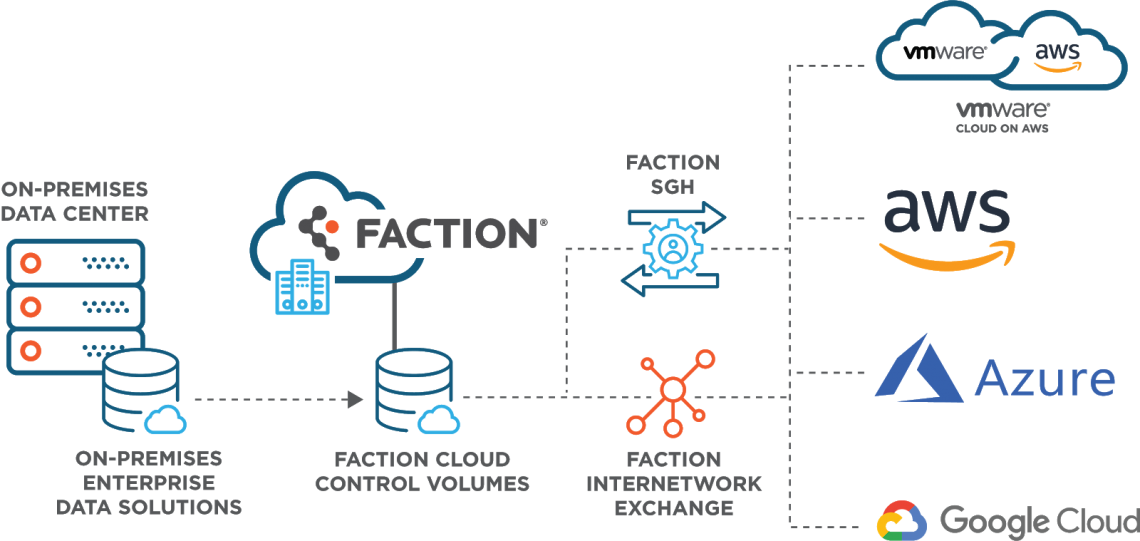
Managed Data Services
Managed Data Services providers can offer the best of both worlds. They have already done the work of ensuring their data centers are located in close proximity to major hyperscale cloud providers, which means they can offer cloud-adjacent data lakes with low-latency, secure connections as well as SLOs suitable for your unique workloads and use cases.
For additional efficiencies, big data management and cloud providers can offer a familiar storage platform that you can easily consume without the burden of managing and supporting yourself, bundled with access and service offerings that connect to and augment resources and services of your clouds of choice.
Conclusion
Leveraging your preferred platform, directly from multiple cloud edges, is critical to crafting a more expert and reliable multi-cloud environment. The shortcomings of existing solutions are laid bare when high performance and multi-cloud access are needed.
Make the cloud edge the central pivot point for your data workflows to enable simultaneous access from multiple clouds and unlock the innovation and flexibility of multi-cloud. This resolves latency and performance bottlenecks from on-premise or un-optimized datacenter locations while greatly improving access and availability.
Seeding data, configuring DR, and migrating data out become nearly painless. Best-of-breed storage services and toolsets are available from any cloud provider. Data security is more digestible, and compliance and security are easier to understand and manage.
Finally, cloud arbitrage is possible, allowing you to deploy or shift workloads depending on cloud provider pricing or resource availability, enabling application-level high availability (HA) across clouds. With data at the center of your multi-cloud world, the options are endless.
Unlock the Unrealized Value of Your Data
Contact the multi-cloud and digital transformation team at Faction today. We make complex multi-cloud technology simple to avoid data gravity black holes. Let us help you unlock more value from your data for better insight and improved data analytics.
About Dan: Dan is a Senior Storage Engineer and Infrastructure Architect who has been with Faction 8 years focusing on hybrid and multi cloud storage architectures.