Dataversity | How Data Deduplication Reduces Cloud Data Costs
The wildfire season in 2020 was particularly intense. The idea of disaster preparedness is always top of mind for many of us here in Colorado and other western states. What would we grab if we had to evacuate instantly? We’d want our family and pets to be safe, of course. And we’d want to secure as many precious photos as possible.
My Great Dane, Miles, takes up significant space in the car — leaving little room for “stuff,” which I wouldn’t have time to grab, anyway. My best bet for saving irreplaceable photographs? Having them on an external drive in my emergency go bag, ensuring that I’ll preserve the images, which I can view, print, or share at a later date. Ensuring that this data — my most meaningful .jpgs — is protected and accessible is part of my personal disaster recovery (DR) plan.
In much the same way that I need to evaluate the space required to store and access things that are most important to me personally, companies must evaluate how to manage their data. How efficient is your data protection strategy? How do you make data accessible regularly, without having to rely on and pay to store multiple copies? In both cases, deduplication can play an important role in your Data Strategy for 2021 and beyond. Here, I’ll review what data duplication is and the two main scenarios in which data deduplication can significantly reduce cloud data costs.
What Is Data Deduplication? And How Does It Work?
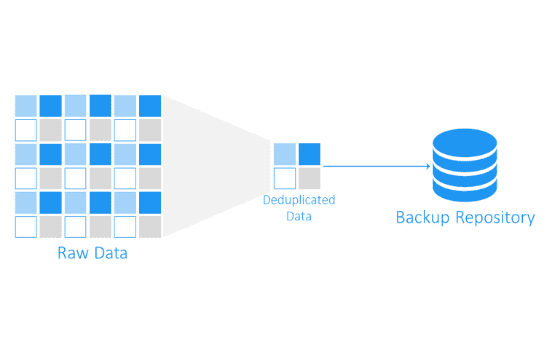
Data deduplication (a.k.a. dedupe) is the process of eliminating multiple blocks of data, thereby eliminating the need to store copies of the data. The end result: Data deduplication shrinks your data footprint, reducing the total amount of storage required. Using less storage space, both on the front and back ends, leads to lower storage costs for your data.
Put into practice, a deduplication rate of 65 times allows you to potentially store 65 TB of data on only 1 TB of logical space, reducing costs commensurately. Dell’s PowerProtect DD, for example, achieves this data efficiency on the back end by not syncing or backing up the same bits of data, but only the deltas.
What Does This Mean for Cloud Data Specifically?
Clouds offer a flexible, utility-based method of storing data off-premises. As you move to the cloud — whether to a single cloud or whether implementing a multi-cloud approach — your data can grow rapidly with storage scaling on-demand with your business requirements. Unfortunately, clouds don’t provide great data efficiencies. The more data, the higher the storage costs. These growing costs can significantly hurt your bottom line. You need your data to be available to you; the cost of storing it shouldn’t be prohibitive.
Organizations with hybrid cloud, multiple public cloud instances, or on-prem data creation can eliminate multiple copies of siloed data. Deduplication provides a single data store with an accessible copy of the data. This provides a streamlined architecture, requiring management of only that single piece of storage. This approach provides advantages for use cases with both low-frequency and high-frequency access to data.
Scenario 1: Public Cloud Protection (Low-Frequency Access)
Deduplication allows you to protect and restore your data in the event of any catastrophic failure or disaster. Data that you don’t access very often, but rely on for backup or in a DR scenario, can be compressed and stored in a small space. This releases you from paying for the highest storage performance tier, meaning you won’t need to pay for large amounts of storage on the back end.
Centralized data protection — with a single namespace and low-latency connection to all the major public clouds — allows you to maximize global deduplication across distributed data backed up from multiple clouds. This also facilitates instant restoration of your data (seen as a native read and write) to any cloud provider, with front-end savings and without the risk of vendor lock-in.
Scenario 2: Dramatically Reduce Data Footprint
Deduplicated data is backed up to cloud-attached storage from both on-premise and clouds, eliminating multiple copies of siloed data. This reduces costs for backup and restore storage and sets the stage for recovery and failover to the organization’s cloud of choice.
Avoid Creating Multiple Copies of Data to Start with
There’s a good chance that your data is growing exponentially. That data growth drives the need for backups, archives of that data, and the need to buy enough storage, whether on-prem or perhaps in a single cloud. Without deduplication, you’ll need to purchase more storage arrays, resulting in higher hardware and management costs. If you’re working with two or three clouds, you’re dealing with two or three times as many complications.
Consider a company that requires 2 PB storage in the cloud. Depending on the type of storage they use, it may take many, many volumes to archive that data. For example, Amazon S3 Glacier has a maximum size of 40 TB per archive. NetApp Cloud Volumes have a 100 TB max per volume, requiring 20 volumes to store 2 PB — along with 20 IPs, 20 namespaces, and 20 points of management. They could store all 2 PB on a cloud-connected Dell EMC Isilon array, but they are still paying for a 1-to-1 amount of storage. Neither of these solutions provides the efficiencies of deduplication. Instead, with a solution that offers up to 65 times deduplication like the PowerProtect mentioned above, they could reduce the size of storage required to back up 2 PB down to possibly 30–35 TB.
The Bottom Line: Multiple Areas for Cost Savings
As you dig into cloud cost optimization efforts, you may realize that you’re paying more than you thought with your current approach. Deduplication facilitates savings by:
1. Reducing the Amount of Storage You Need to Buy: Just as a CD of photos provides streamlined storage functionality that allows you to view or print images as needed, data deduplication minimizes the amount of storage required — by 2 times or more.
2. Reducing the Networking You Need to Buy: By architecting for a single, accessible copy of your data, your organization retains control with a cloud-adjacent service. This also prevents vendor lock-in and associated expenses, such as egress charges.
3. Reducing Management Overhead: Centralizing your data protection for all clouds (including AWS, Azure, Google Cloud Platform, and VMware Cloud on AWS) streamlines management, reducing associated costs, complexities, and sprawl.
Ultimately, data deduplication efforts can yield exponential efficiencies and savings as part of a well-managed Data Strategy.