Hybrid Cloud and Multi-cloud: The Differences and Advantages of Each
People often use the terms hybrid cloud and multi-cloud interchangeably. It can get especially confusing because the two can co-exist, and such combinations are becoming more and more common. However, there are defined differences between the two.
The majority of enterprises today are both hybrid cloud and multi-cloud environments. 78% of organizations in 2021 are using a hybrid cloud mix of private and public clouds. Most of those also engage multiple public cloud vendors, which means they are both hybrid and, at a minimum, using multiple clouds.
What Is the Difference Between Hybrid Cloud and Multi-Cloud?
In a multi-cloud environment, organizations use services from multiple public cloud providers, such as AWS, Google Cloud, Oracle Cloud, and Azure. Typically, enterprises mix and match cloud services to meet different workload needs, realize cost advantages, and availability.
Multi-cloud uses multiple cloud computing and storage resources and combines that into a single network architecture.
For example, an enterprise may use Oracle Cloud for database workloads, Azure for development environments, AWS for DR workloads, and Google Cloud for analytics. They mix multiple public clouds.
A hybrid cloud solution is a mix of public cloud and private cloud infrastructure. Organizations might use a private cloud to store sensitive data in an on-premises or colocated data center connected by a private cloud while offloading other workloads to a public cloud service or multiple public clouds.
Hybrid clouds include private clouds and public clouds. Organizations with a multi-cloud strategy utilize multiple public clouds and may (or may not) incorporate a private cloud.
Can a Hybrid Cloud Be Used in a Multi-Cloud Environment?
A hybrid cloud and a multi-cloud environment can co-exist. By combining on-premises or private cloud, with multiple public clouds, their architecture is both hybrid cloud and multi-cloud.
So, hybrid clouds can be multi-cloud if multiple public clouds are used. Multi-cloud environments can be hybrid if multiple public clouds and private clouds are used together.
Comparing Multi-Cloud Architecture with Hybrid Architecture
The biggest differentiator between the two when it comes to IT architecture is the location of the resources that are not in the cloud.
Hybrid Cloud Architecture
In a hybrid cloud environment, on-prem resources are used. This might include servers, data centers, storage, networking, and monitoring among others. The public cloud is also used, but the combined architecture has single, policy-based governance. This extends the capabilities of the on-prem solution without compromising security or operation.
Businesses that are undergoing digital transformation often start with a hybrid cloud environment to transition through migration before jumping into full-scale cloud deployments.
In a tiered hybrid cloud model, frontend applications are migrated to the cloud. These applications are stateless since they do not handle data volume and tend to have fewer dependencies. Frontend applications have more frequent updates, which can be automated much easier when they run on the public cloud.
Multi-Cloud Architecture
In a multi-cloud structure, all of the resources are in the cloud at one provider delivering multiple cloud computing services or utilizing multiple providers and/or colocation facilities. Most commonly, multiple cloud service providers are engaged. Computing and storage are spread over a distributed network.
Multi-cloud architecture can be designed to handle several different use cases. For example, you can choose to replicate applications across multiple cloud services and distribute workloads to balance the load. You can choose to segment workloads based on vendor strengths, cost efficiencies, or segregate workflows.
You may also want to distribute time-sensitive data that requires low latency. By moving data traffic closer to end users, you can reduce the latency inherent in cloud services that are delivered from distant locations. This can be important for businesses that have multiple office locations, operate in geographically different areas, or do business globally.
Advantages of a Hybrid Cloud Environment
One of the key advantages of a hybrid cloud solution is allowing workloads, application orchestration, and data portability across multiple environments. This allows organizations to coordinate workloads between connected computing environments, orchestrate processes across multiple applications, and exercise greater control and governance over resources.
Here are some of the top reasons that IT leaders deploy hybrid clouds:
- Cloud Bursting
Applications can run normally on a company’s private cloud. When there is increased demand, applications “burst” into the public cloud to ensure seamless operations. This provides a company with a way to meet periodic spikes in usage without having to overprovision for normal business workloads. - Remote Employees or Distributed Workforce
By making applications and data available in the cloud, they can be accessed from anywhere there is a viable internet connection. A public cloud connection allows remote employees to access on-premises data and applications on the private cloud. This has become especially important as two-thirds of enterprises plan to permanently shift some employees to work remotely post-COVID. - Compliance and Regulations
There are strict rules for governance in many industries regarding how and where data is stored. Several countries have passed data localization laws requiring companies to store personal data on their customers in-country rather than exporting it to central servers. Hybrid cloud solutions allow businesses to store consumer data locally in the public cloud if required. - Security
Companies can minimize security threats by storing sensitive and proprietary data on private clouds and on-premises data centers, which decreases the likelihood of cyberattacks. Less sensitive data can still be stored on public clouds. - Cost-Efficiency
A hybrid cloud lets you reserve a private cloud for sensitive information and mission-critical functions. Cloud services can also be provisioned to load shift to minimize spending. - Reduce CapEx
Building out your data center for peak use is expensive. Hardware, networking, software, and real estate add up quickly. Leveraging the cloud’s pay-for-what-you-use cost models shift expenditures from costly CapEx to OpEx. - Rapid Scalability
Public cloud services can also be scaled up quickly without having to add on-prem data centers or additional hardware.
In practice, hybrid cloud solutions are often used to separate development and testing environments, migrate workloads to the cloud over time or maintain high availability.
Advantages of a Multi-Cloud Environment
A multi-cloud environment also provides a variety of benefits for organizations, including redundancy, optimization, and avoiding vendor lock.
- Innovation
The biggest advantage of a multi-cloud strategy is providing the flexibility needed for rapid innovation. Multi-cloud lets you take advantage of best-in-class service that each cloud provider offers without having to compromise due to provider limitations. - Business Resiliency
Even major public cloud providers can experience outages, but a multi-cloud approach protects your business by enabling the flexibility to run applications on multiple clouds and share loads seamlessly. If one cloud service goes down, end users won’t notice a difference. - Avoid Vendor Lock-in
A recent survey of IT leaders ranked avoiding vendor lock-in as their top priority. 46% of those surveyed said they want the flexibility to quickly change providers if service contracts are not fulfilled. When you utilize multiple cloud providers, you aren’t locked into any one provider. - Optimization
Each cloud service provider has strengths and weaknesses. In a multi-cloud environment, you can run application workloads in the environment that’s best suited for it. Your data strategy might be different on Azure vs. Google vs. AWS. With multi-cloud, you can choose which cloud platform works best for individual solutions. - Cost Optimization
You can take advantage of pricing options for computing resources and storage by using multiple cloud providers. By projecting your storage and workload requirements, you can allocate IT resources to the most cost-effective provider.
Another significant advantage to adopting a multi-cloud strategy is to better manage data gravity. Moving or migrating large data sets is time-consuming and can be expensive. That’s why most enterprises store their data in proximity to the applications and services used for analysis. Data gravity can force companies to deploy related apps or services with the same provider even if there are more cost-effective solutions available on another cloud platform. This data gravity holds you in place even when you want to fly!
By adopting a multi-cloud data solution that connects to multiple clouds, you can choose where you store data sets and applications for best practices. A multi-cloud solution will plan out data location, availability, and latency to minimize data gravity and reduced data duplication.
Many companies also use multi-cloud as part of their data strategy for backup and archiving to achieve robust business continuity and disaster recovery.
Managing Hybrid Cloud and Multi-Cloud Environments
Moving to a hybrid or a multi-cloud environment can increase the complexity. When you add additional pathways, mix on-prem and remote resources, or spread data and applications across multiple cloud services, it can easily become unmanageable without a solid plan in place.
Many businesses wind up with a hybrid cloud architecture or multi-cloud environments haphazardly. As new needs arise, more resources are added. This can create wasteful spending and increase the complexity of management.
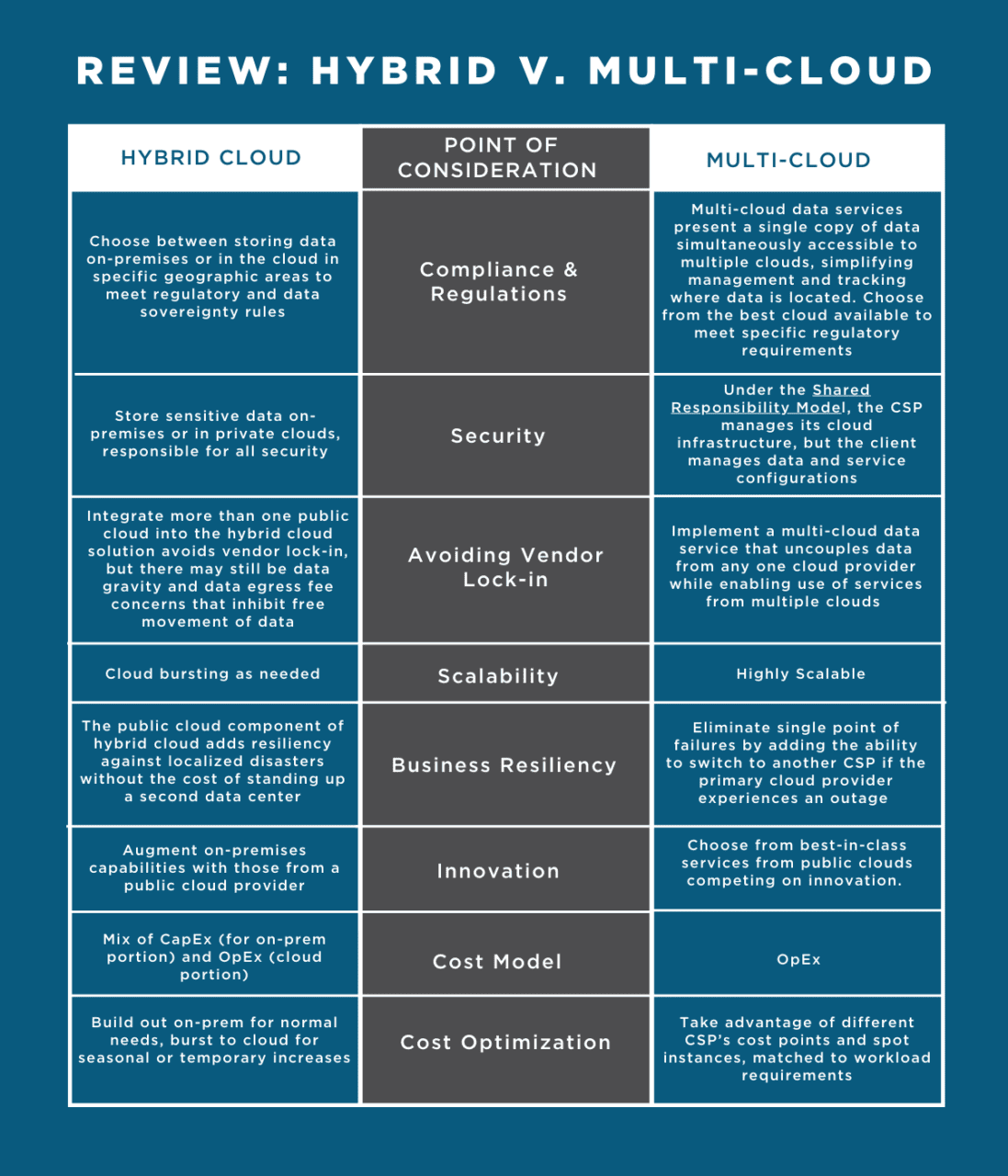
Review: Hybrid Vs. Multi-Cloud
Regardless of which direction you go with your IT environment, it’s essential that you plan it out carefully. Your strategic plan needs to go well beyond your current needs and account for your long-term goals and business priorities. Every decision you make should be viewed through these lenses.
You should first define the objectives and business case for deployment. You will also need to review your existing infrastructure and identify current applications and workloads as well as future plans. Portfolio discovery takes time to do right. Missed dependencies can cause significant problems.
When adopting a hybrid cloud or multi-cloud strategy, a master data management plan is also crucial. Without a plan, data often gets duplicated or delinked. Consolidating and simplifying your data can simplify workload portability and management.
Another factor to consider is data access. Some cloud service providers charge more for hot storage that you need to retrieve quickly versus cool or archival storage. You may also pay for data extraction, so it’s important to understand the nuances of your service level agreements.
You’ll also want to decide on a governance framework, an overarching security plan, and a centralized solution for monitoring.
It can get complex. That’s why we’re here to help. At Faction, we are dedicated to making complex hybrid cloud and multi-cloud environments simple and accessible so you get more value from your data.
If you want to compete — and win — with data, you need a multi-cloud strategy to drive innovation and growth. Request a quote today and let us show you how we can transform your data strategy.